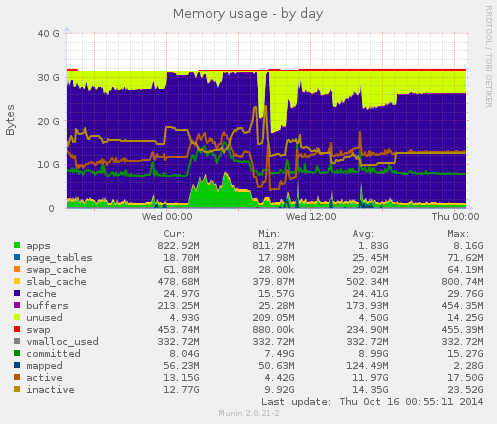
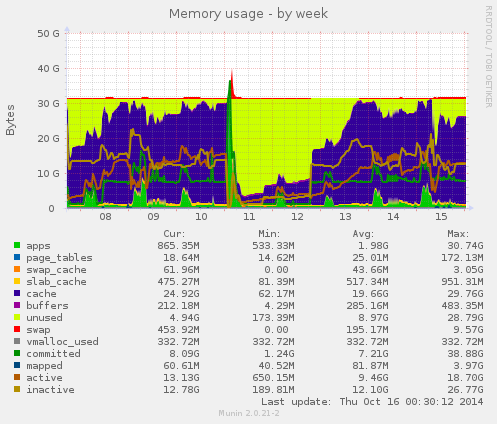
Интересные дела…
user@server:~$ di Filesystem Mount Size Used Avail %Used fs Type /dev/md0 / 1.9G 0.4G 1.4G 26% ext4 udev /dev 5.9G 0.0G 5.9G 0% tmpfs tmpfs /dev/shm 5.9G 0.0G 5.9G 0% tmpfs tmpfs /lib/init/rw 5.9G 0.0G 5.9G 0% tmpfs /dev/shm /run/shm 5.9G 0.0G 5.9G 0% none /dev/md1 /usr 9.4G 0.8G 8.1G 14% ext4 /dev/md3 /var 1.8T 0.1T 1.6T 11% ext4 user@server:~$ df Filesystem 1K-blocks Used Available Use% Mounted on /dev/md0 1966404 416816 1449700 23% / tmpfs 6163396 0 6163396 0% /lib/init/rw udev 6157924 228 6157696 1% /dev tmpfs 6163396 4 6163392 1% /dev/shm /dev/md1 9842136 833200 8508972 9% /usr /dev/md3 1899242804 108050616 1694716184 6% /var